Loading...
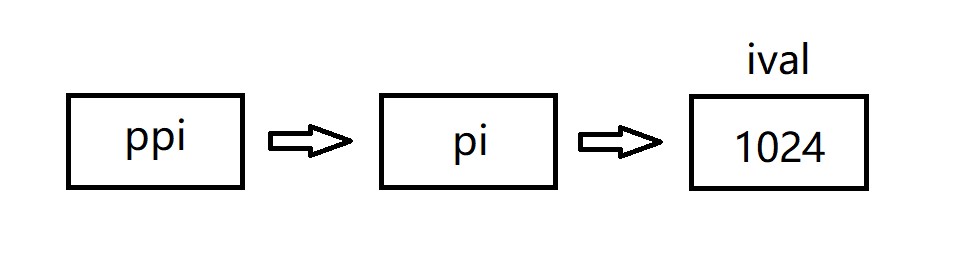
C++ string and vector string 标准库类型 string 表示可变长的字符序列...
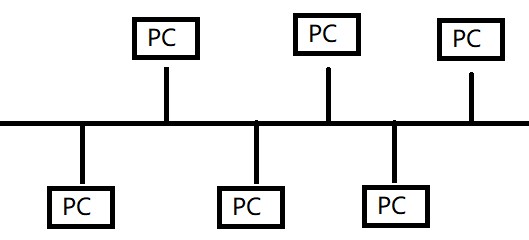
因特网概述 网络、互连网和因特网 网络(Network)由若干个结点(Node)和连接这些结点的链路(L...